Запуск Ollama на Synology

Привет! Недавно, приобретя сетевое хранилище от Synology я решил потестировать на нем пару языковых моделей.
Тестировать я собираюсь на DS423+ от Synology. Машина имеет Intel Celeron J4125 с 4 ядрами на борту и базовой частотой в 2ГГц. Поставляется DS423+ с 2гб оперативной памяти, но даже для маленькой модели нам потребуется как минимум 4гб. Благо, на эту модель можно спокойно поставить модуль расширения что я и сделал. Некоторые ставят больше, но Synology не рекомендует этого делать.
Запускать Ollama мы будем в Docker-е, так как система DSM стоящая на нем не позволяет удобно ставить свои приложения. Также мы поставим Open Web UI для удобного взаимодействия с моделью. Зайдя в веб интерфейс я сразу поставил несколько небольших моделей: tinyllama на 1.1b параметров, llama3.2 на 1b параметров и gemma2 на 2b параметров. Ниже приовожу опыт работы каждой модели:
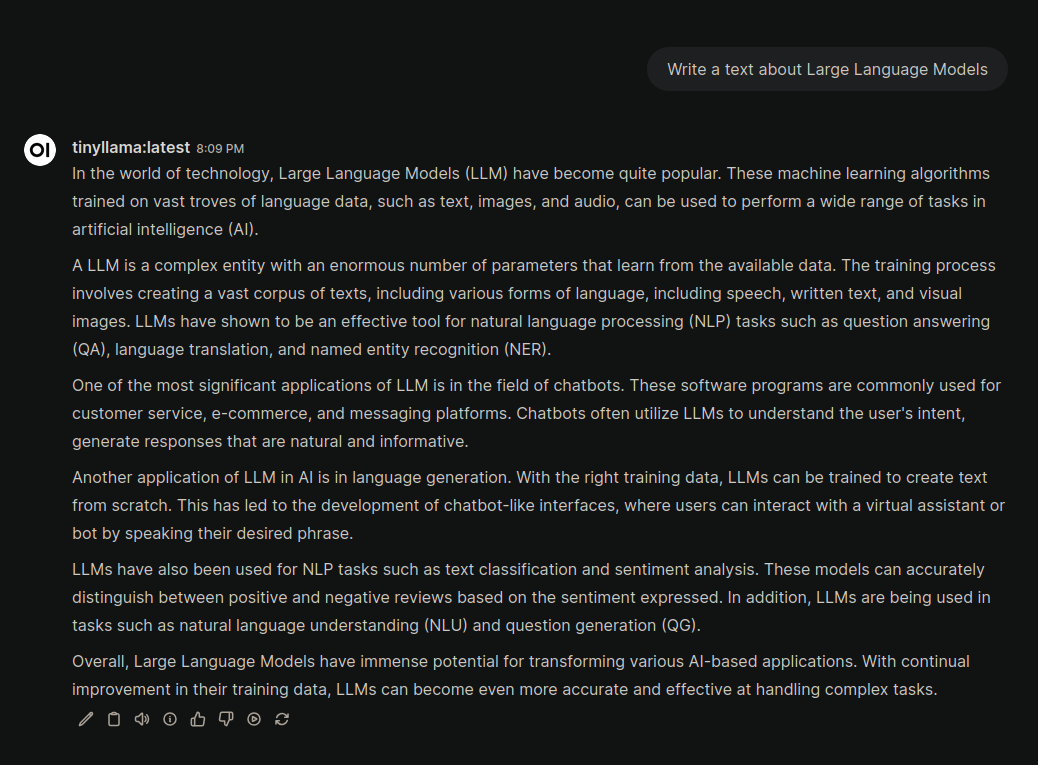
Начнем с самой небольшой модели. Промпт tinyllama обрабатывала около 30 секунд и сразу же начала писать не на ту тему которую я попросил. После уточнения подробностей модель написала неплохой текст. Скорость ответа была 2 токена в секунду.
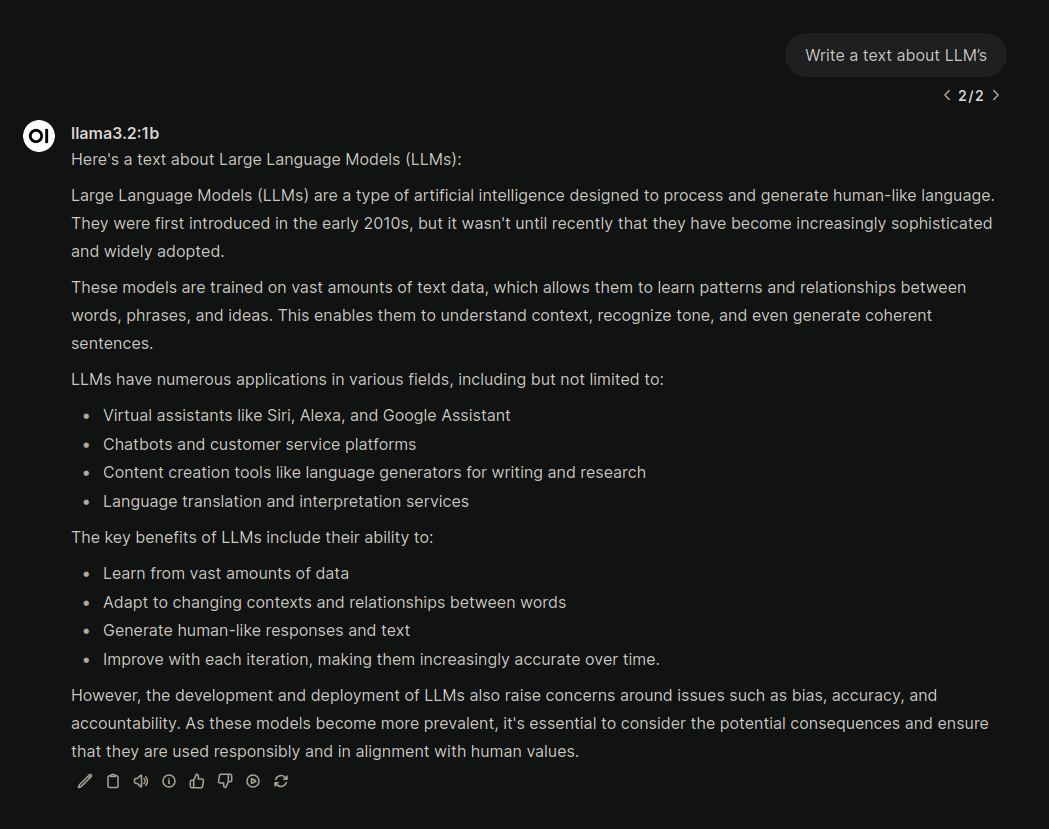
Модель несколько секунд обрабатывала запрос (хотя иногда это может происходить пару минут) после чего стала отвечать со скоростью 1.6 токена в секунду. При этом процессор был загружен в 100% из за чего другие приложения были очень медленными. В общем промпт просящий написать небольшой текст про языковые модели занял 4 минуты.
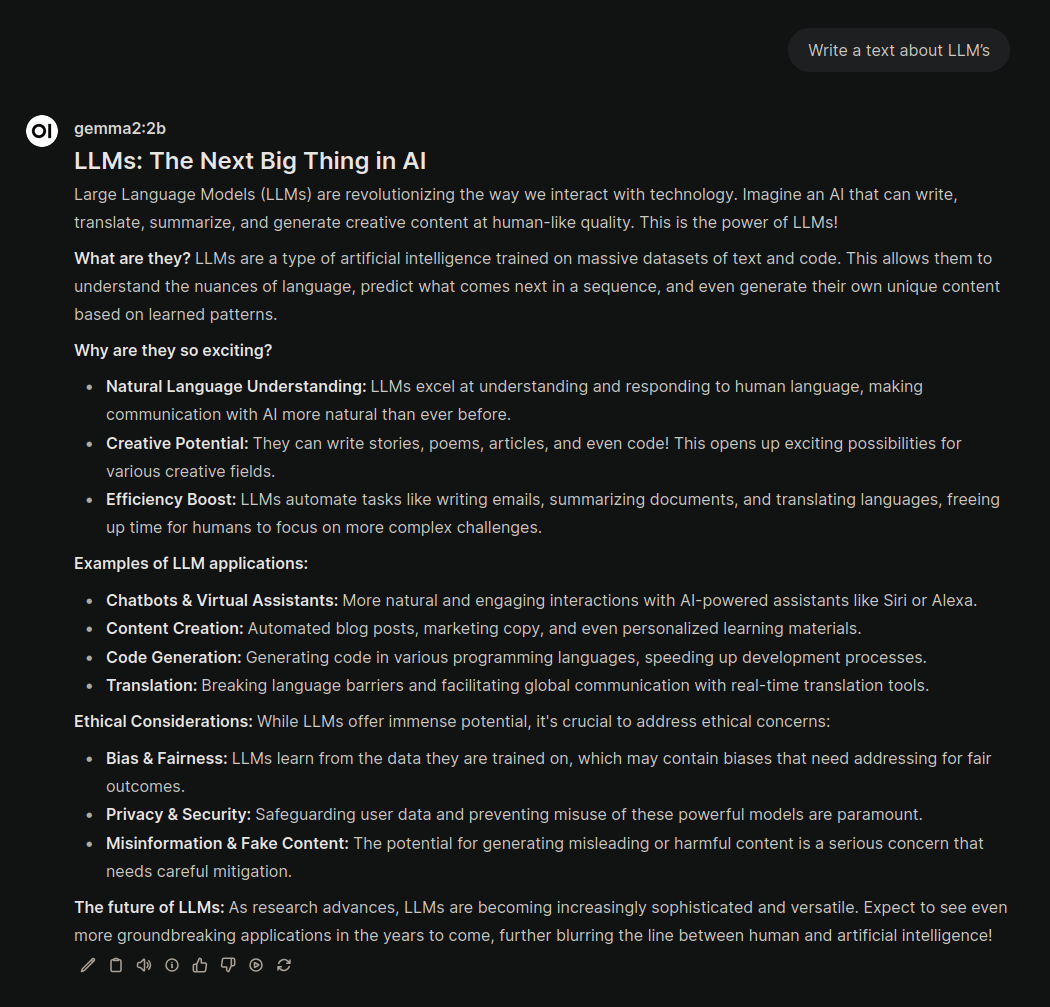
Модели понадобилось более 8 минут чтобы обработать запрос. Модель была намного медленее llama3.2 на 1b выдвавая всего 0,5 токенов в секунду, но при этом качество выдаваемого текста повысилось. Весь текст Gemma2 написала за 20 минут
Использование языковых моделей даже на маломощных устройствах возможна, если вы нуждаетесь в суммаризации текста, проверки орфографии и т.д, но работа с сложными задачами требует больших моделей и соответственно больше производительности.